
Designing AI-Assisted Review for High-Stakes Exam Integrity
How an AI-flagged review queue became a structured triage workstation - reducing review time from 3+ hours to under 10 minutes per case while keeping human judgment firmly in the loop. Validated at 4.5 / 5 satisfaction across reviewers in a real adjudication setting.
The shift
From three hours per case to under ten - without the AI making the call.
An AI flagging system was already producing probability scores on potential exam-integrity violations. The workflow underneath it wasn't. Reviewers were opening flagged cases, hunting through video, scrubbing for context, and rebuilding evidence from scratch on every adjudication. Investigations that should have taken minutes were taking hours.
The brief: design a workstation that turns AI signals into a fast, defensible human decision. Not automation. Triage with judgment.
I led product design end-to-end, partnering with Product, Engineering, AI/ML, and the adjudication operations team that would actually use the tool every day.
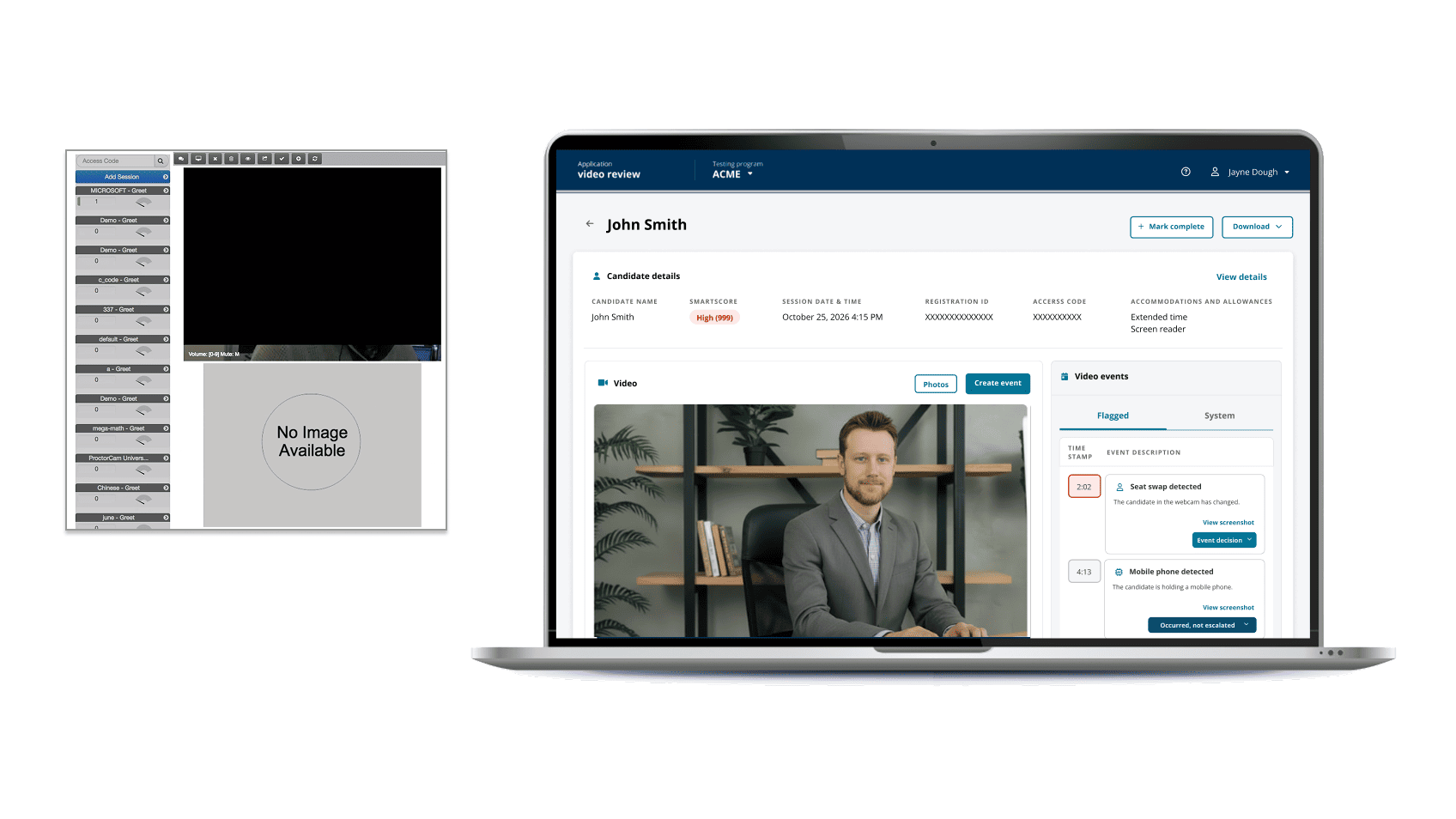
Where the model alone falls short
A confidence score is not an investigation.
The AI was good at flagging anomalies. It was not good at explaining them, and it had no model of the human work that turns "this looks suspicious" into a defensible adjudication that holds up under appeal.
- Probability scores without supporting evidence increase automation bias - reviewers either over-trust the flag or learn to dismiss it.
- Video evidence is dense; without structured cues, reviewers re-watch entire sessions hunting for the moment that matters.
- Adjudication decisions need to be auditable. The reviewer needs to show their reasoning, not just record a verdict.
Designing around the model meant designing for the gaps the model couldn't close on its own.
Understanding the reviewer
The user is not a moderator. The user is a calibrated decision-maker under audit.
I spent time with reviewers and adjudication leads to understand how decisions actually got made. Three observations shaped everything that came after.
Reviewers don't want the AI to decide. They want it to point. The case study is a small set of decisions per session, each one consequential; the AI's job is to compress hours of context into a focused starting point.
Evidence is the spine of trust. A flag without a visible reason erodes confidence faster than no flag at all. Reviewers trust transparent uncertainty more than confident opacity.
Adjudication is a written record. Whatever the reviewer decides will be reviewed downstream - by investigators, by clients, sometimes in legal proceedings. The workstation has to leave a trail.
Principles I held to
Calibrated transparency, evidence-first, and the human stays in the loop.
1. Show the AI's evidence, not its confidence. Probability scores are abstractions; timestamped video moments are not. The dashboard surfaces the specific evidence that triggered each flag, not a raw confidence number.
2. Make uncertainty honest. When the model is unsure, the UI says so. Calibrated transparency builds more trust than confident performance.
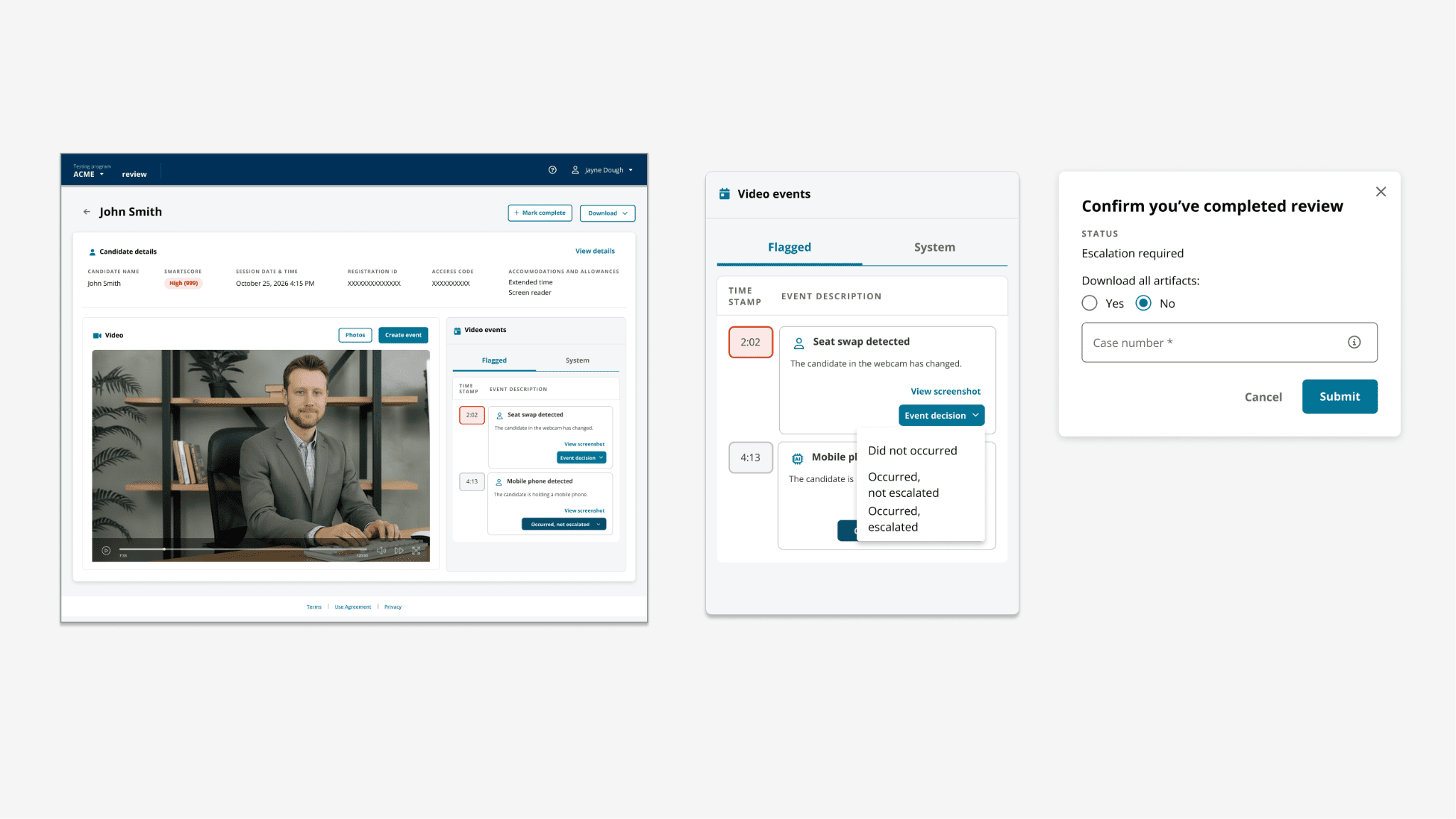
3. Recovery as easy as the happy path. Override, escalate, and request-more-info are first-class actions, not buried.
4. Every decision auditable by default. The workstation captures the reviewer's reasoning structure inline - not as an after-the-fact form.
Six decisions that shaped the workstation
From flagged queue to recorded verdict.
1. A triage dashboard organized by reviewer attention, not chronology. Cases sort by AI-detected severity and reviewer-assigned priority, with status badges that make queue state legible at a glance.
2. An evidence canvas with timestamped flags layered on the video. Reviewers jump directly to the moments the AI surfaced, not to minute zero. Hover-state context tells them why each flag triggered.
3. Structured decision paths, not free-text fields. The reviewer chooses from a constrained set of outcomes that map to adjudication taxonomy - which makes downstream calibration possible and reduces ambiguity in audit.
4. Explainability cues attached to every flag. "Why this was flagged" is one click away on every detection, every time.
5. A side-by-side comparison view for reviewers who need to compare a flagged moment against a baseline frame - the workstation supports this directly rather than asking them to open two windows.
6. An audit trail that reads like a story. Every action - flag opened, evidence reviewed, outcome chosen, escalation made - is captured in chronological order so the next reviewer or auditor can follow the reasoning without asking for a debrief.
Validating with real reviewers
Confidential usability data across the workstation's core surfaces.
We ran usability validation with reviewers who would actually use the workstation in production. Six reviewers, evaluated against the dashboard, video review canvas, and overall workflow.
- Dashboard: 4.6 / 5 - the highest-rated surface in the study, validating the evidence-first triage approach
- Video Review canvas: 4.3 / 5 - timestamped flags and explainability cues landed
- Overall workstation: 4.5 / 5
Most importantly: reviewer-investigator agreement on flagged cases hit 98%. The workstation didn't just make reviewers faster - it made their decisions converge with the people who reviewed them downstream.
What it unlocked
Speed plus defensibility - the combination that matters.
The headline number was the throughput change: 3+ hours per case down to under 10 minutes. But the durable value was the agreement rate. A workstation that's 10× faster but produces decisions that don't hold up downstream isn't a win; it's a liability. The 98% agreement number proves the speed didn't come at the cost of judgment.
The structured decision paths also created a calibration loop the AI didn't have before. Every reviewer outcome is now a labeled training signal that can refine the flagging model over time - the human-in-the-loop pattern isn't just protecting decisions, it's improving the system.
What I took from this
Honest AI is more trustworthy than confident AI.
The lesson I carry forward from this work: calibrated transparency builds more trust than performed certainty. The dashboard scored highest because it showed reviewers the AI's evidence rather than its confidence - and that single design choice anchors how I now think about every human-AI workflow.
The other thing I took from this: in trust-critical domains, the right output of a design isn't a faster decision; it's a defensible faster decision. Speed and audit are not in tension when the workstation is designed for both at once.