Designing AI-Guided Environment Validation for Remote Testing
How a four-photo room-scan flow was redesigned into a candidate-led 360-degree AI-validated video scan - with explicit AI accuracy targets (70% / 20% noise ceiling), traffic-light triage to live greeters, and a coaching UX validated against real session data.
The strategic frame
A live-proctoring step that costs minutes per candidate at scale.
Every remote-proctored exam requires the candidate to verify their workspace meets the test sponsor's requirements. Historically that meant capturing four still photos - front, left, right, back - and falling through to a live greeter for a real-time 360-degree scan if anything looked off.
The greeter step was the bottleneck. Multiply minutes per failed scan across the volume of a global remote-proctoring platform and the workspace check became a measurable line item on the cost-to-deliver of every exam.
Leadership framed the ask in plain terms: shift the workspace check to an AI-validated 360-degree video scan, performed earlier in the journey, with the AI doing first-pass triage so live greeters intervene only on real exceptions.
I led product design for the candidate-facing scan, partnering with Product, Engineering, AI/ML, CX Research, and live-greeter operations.
Why the four-photo flow had to change
It put the work in the wrong place at the wrong time.
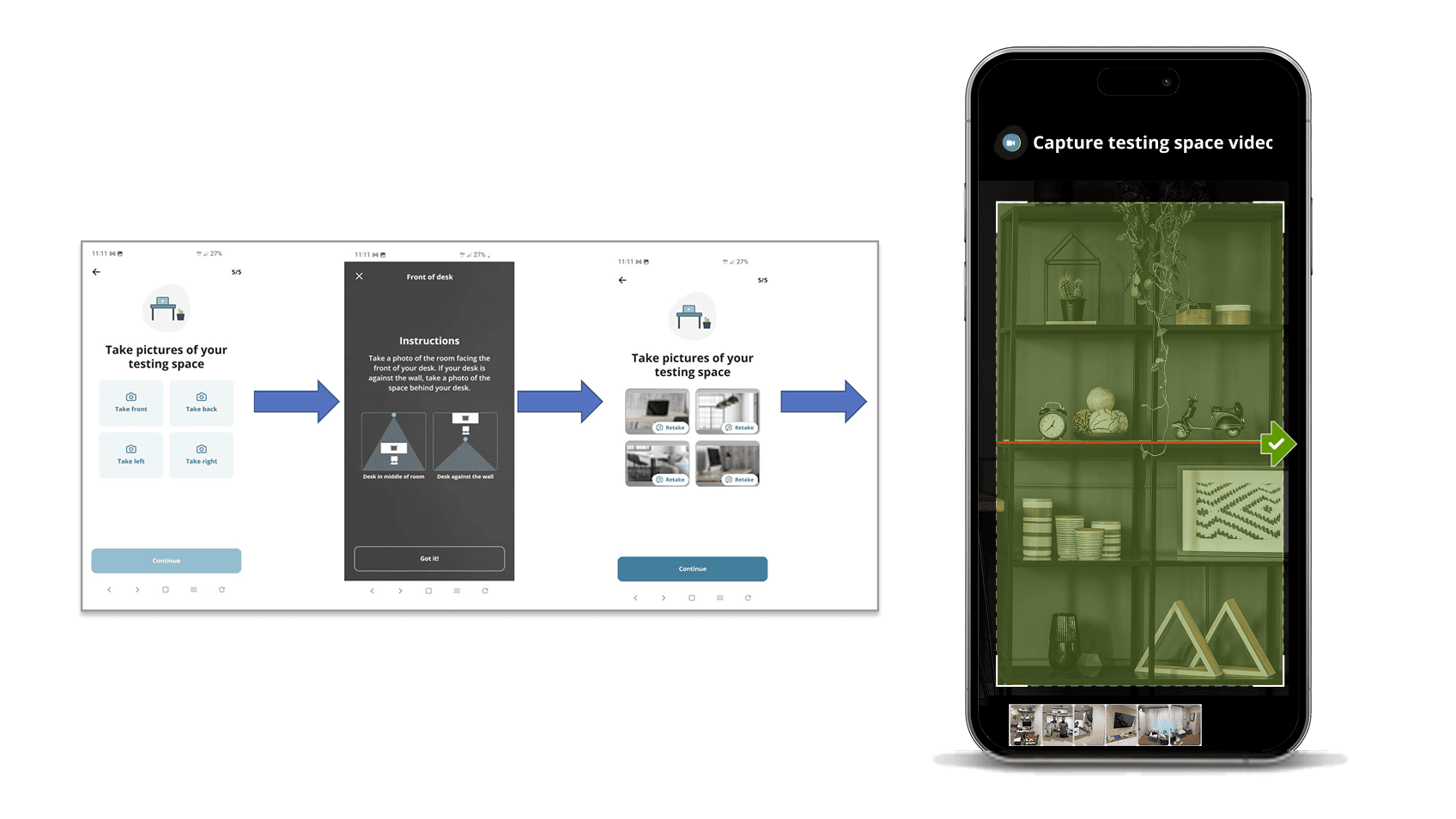
The legacy four-photo flow had three failure modes that compounded.
- It happened too late. Candidates discovered a non-compliant workspace at check-in, when they were already keyed up and racing the clock.
- It captured too little. Four still photos miss the spaces between angles. A notebook just outside the frame passed verification.
- It made greeters the bottleneck for every edge case. The only escalation path was a live video call - expensive at small scale, unsustainable at global scale.
How I framed the work
From enforcement to coaching - with the AI as a calibrated collaborator, not a gatekeeper.
Two design principles set the direction.
Shift the candidate-facing tone from enforcement to coaching. The legacy flow read like a checkpoint. The redesign treats workspace prep as a guided step - the candidate is being helped to get this right, not graded on it.
Design the AI as a calibrated collaborator, not a gatekeeper. The vision document set explicit targets: 70% AI accuracy for detecting out-of-policy items, with a 20% maximum noise rate. Those numbers say something important: the AI will be wrong sometimes, in known ways, at known rates. The UX has to make that honest.
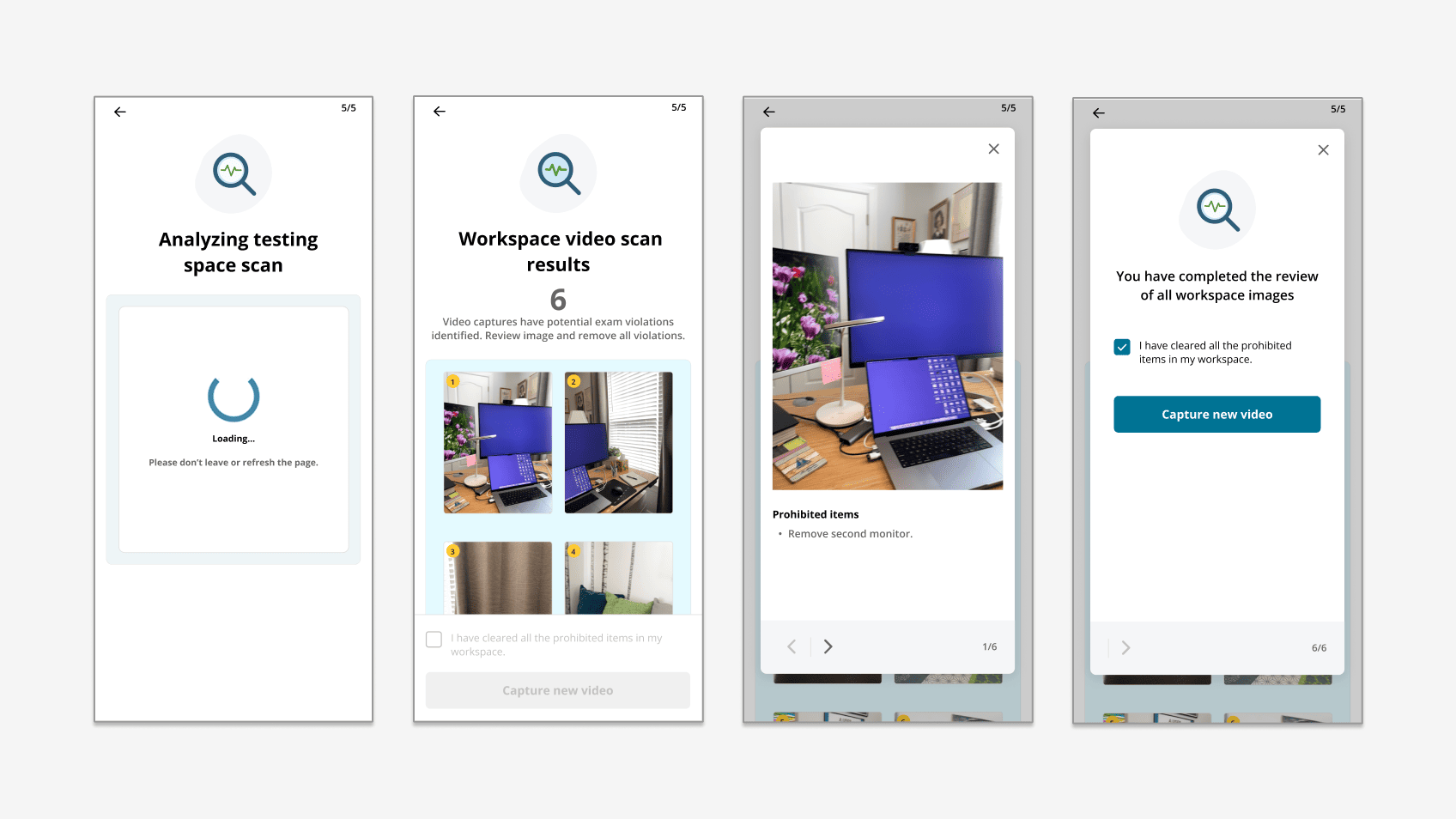
That principle led directly to a traffic-light triage handoff - GREEN-APPROVED when AI checks pass, YELLOW-REVIEW when AI cannot process, RED-PROBLEM when retries are exhausted - with greeters labeling AI outcomes as True or False to feed the calibration loop. Textbook human-in-the-loop: the AI does volume; humans do edge cases and supervision.
Constraints that shaped every screen
A trust-critical system designed under real production conditions.
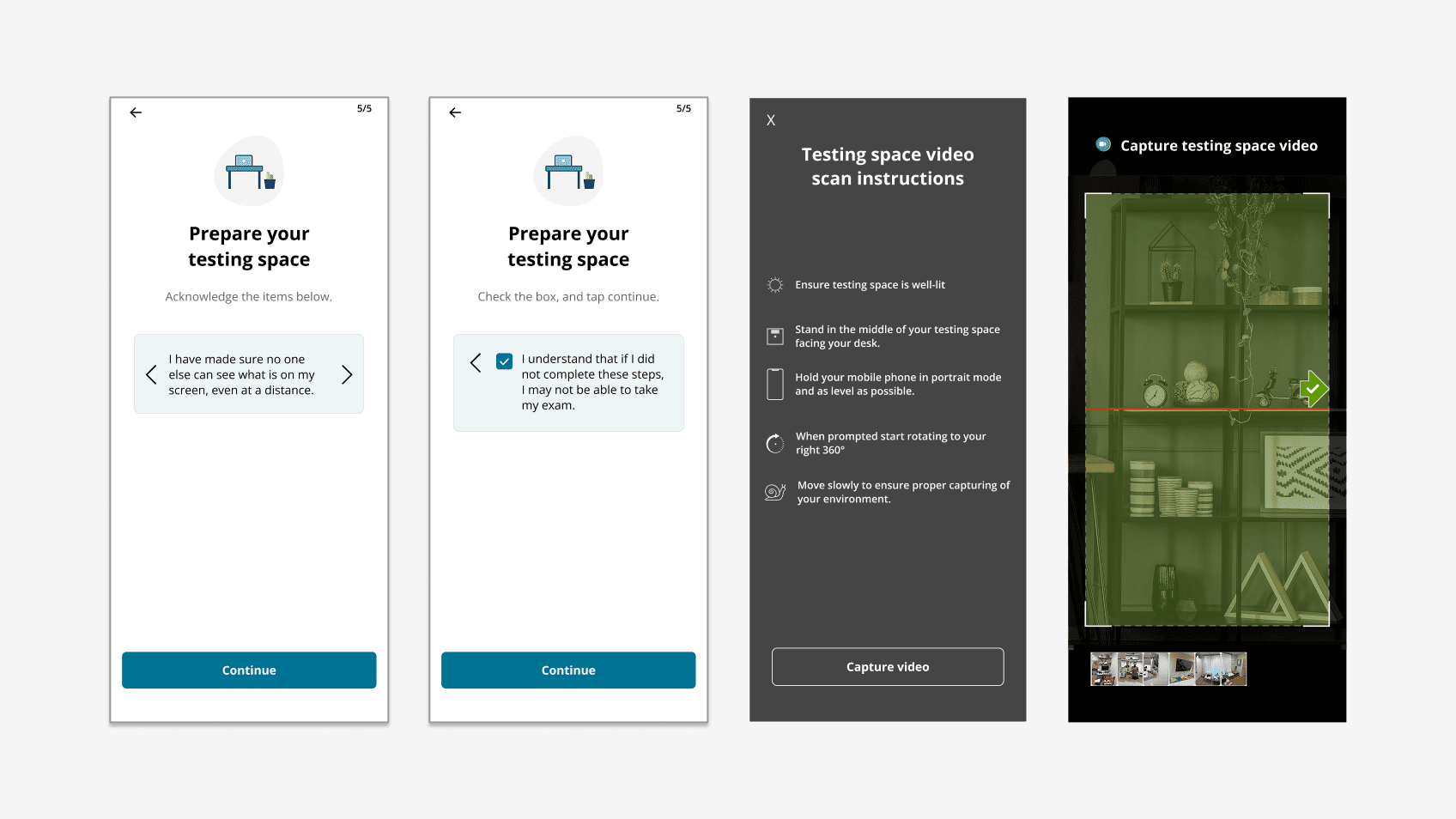
- The capture device is the candidate's own phone. Newer iPhones and older Androids both have to work, on networks the platform doesn't control.
- The AI is permitted to fail. Some clients can't allow AI processing on regulatory grounds; the flow keeps working with the AI off, falling through to greeter review.
- Retries are configurable, not infinite. Clients set the ceiling. The UX honors it without making the candidate feel trapped.
- Compliance and governance. Strict data-retention, auditability, and security standards apply throughout - common consumer-UX shortcuts (silent retries, ambient autosaves) aren't available.
Six decisions that shaped the candidate flow
From acknowledgment to handoff - what I held to.
1. Acknowledge the requirements as a checklist. Four icon-led topic groups so candidates scan, not read paragraphs. Tied to the email sent before exam day so it reads as continuity.
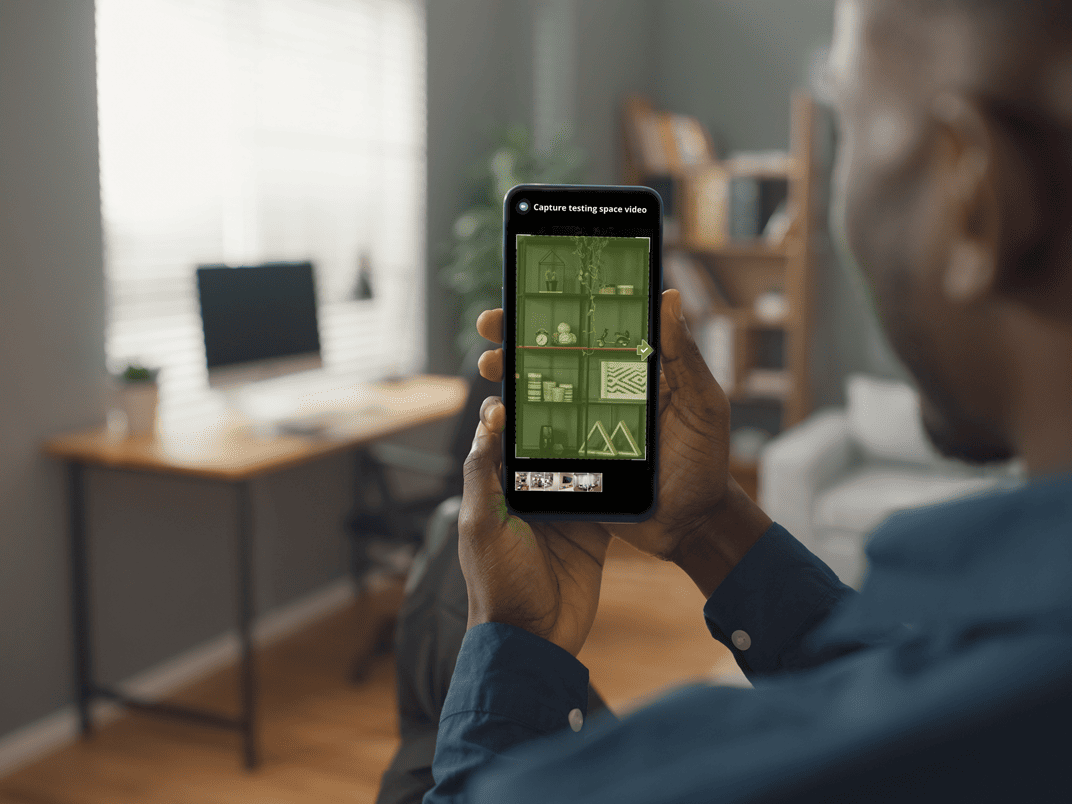
2. Preview the scan before it starts. Capture instructions show a phone in portrait mode, an alignment cue, and slow-rotation guidance. Nothing about the actual capture should be a surprise.
3. Treat capture as live coaching. Real-time prompts during the scan guide candidates without cutting them off.
4. Make recovery as visible as success. A failed capture has to look failed - explicit error state, visible Restart scan action, no encouragement copy reserved for genuine progress.
5. Cap retries with an explicit greeter exit. A "Talk to a greeter" path appears on the capture screen after the second attempt - surfaced before frustration accumulates.
6. Make the results page do the explainability work. When the AI flags a violation, the results screen shows the actual problem frames from the candidate's own video, with plain-language descriptions. This surface scored highest in validation - 4.1 / 5 - because the AI's reasoning was visible.
What 6 candidates told us
Real session data, including a finding that pre-empted launch.
August 2025 validation: 6 participants, 3 iPhone and 3 Android, 45-minute remote sessions with phone-screen sharing.
Numeric ratings (1-5 scale):
- Workspace requirements: 3.6
- Scanner tool: 3.4 (the lowest-rated surface, drove the most actionable findings)
- Pages showing issues: 4.1 (highest-rated; validated the AI-explainability approach)
- Overall: 3.8
The headline finding: no participant succeeded on their first scan attempt. Every candidate had to restart between 1 and 4 times before their first successful capture. The scanner was reading honest candidate motion as failure - the alignment cue triggered restarts faster than candidates could correct.
Other key signals: "you're doing great" copy appearing during failure states was misleading. Scan-results thumbnails didn't read as clickable. The completion graphic (a ladder) didn't communicate "you're done." Candidates wanted explicit greeter-bypass after the second failed attempt. One candidate captured the qualitative read directly: "It adds stress to an already stressful situation."
Where it goes next
Findings translated into a launch-readiness checklist.
- Tune capture sensitivity - the single biggest unlock for first-attempt success rates.
- Rebuild the failure state - explicit error copy, clear Restart action, alignment arrow → stop-sign during failures.
- Surface a candidate-led greeter escape after the second failed attempt.
- Add affordance to scan-result thumbnails - tap-to-expand and scroll-for-more without instruction.
- Replace the ladder graphic with imagery that communicates next-step continuity.
- Re-test with external candidates on broader hardware diversity before launch.
What I took from this
Honest AI is more trustworthy than confident AI.
The page that scored highest - 4.1 / 5, well above any other surface - was the one that showed candidates the AI's actual evidence rather than its confidence. That's calibrated transparency in practice, and it's the same lesson I now bring to every AI-assisted workflow I work on.
The corollary: aiming for 70% AI accuracy with a 20% noise ceiling means roughly one in three candidates will see an AI decision they disagree with. The candidate's escape hatch matters more than the AI's accuracy. The traffic-light triage and the candidate-led greeter exit are the parts of this design I'd port forward into any agentic-AI workflow.